
퍼시스턴스 프레임워크란 무엇인가요?
퍼시스턴스 프레임워크는 데이터베이스에 데이터를 저장하고 필요할 때 다시 불러오는 작업을 지원합니다.
주요 목적은 애플리케이션과 데이터베이스 간의 데이터 전송을 효율적이고 일관성 있게 관리하는 것입니다.
어떤 역할을 하나요?
1. 데이터 매핑
애플리케이션의 데이터 구조를 DB의 테이블과 매핑하여 데이터와 데이터베이스 간의 전송을 자동화하여 쉽게 DB를 조작할 수 있게 합니다. 자바와 같은 객체 지향 언어에서는 '객체'를 테이블과 매핑합니다.
2. 데이터베이스 연동
DB 연결, SQL 쿼리 실행, 결과 매핑 등의 작업을 관리합니다.
3. 트랜잭션, 캐시 관리
데이터 일관성과 무결성을 유지하기 위해 트랜잭션을 시작하고, 커밋하거나 롤백하는 과정을 자동으로 처리합니다.
자주 사용하는 데이터를 캐시하여 DB 접근 횟수를 줄이고, 응답 시간을 단축하여 애플리케이션의 성능을 최적화합니다.
4. 데이터베이스 독립성 제공
여러 종류의 데이터베이스를 지원하기 때문에, 특정 데이터베이스에 종속되지 않고 유연한 설계를 할 수 있게 해줍니다.
이로 인해, 데이터베이스를 변경해야 할 때 많은 부분을 수정하지 않고도 쉽게 변경할 수 있습니다.
5. 스키마 생성 및 관리
MyBatis는 스키마의 생성, 관리를 직접적으로 지원하지 않지만, JPA와 같은 프레임워크는 데이터베이스 스키마를 자동으로 생성하고, 변경 사항을 관리해주는 기능도 지원해줍니다.
대표적으론 어떤 것들이 있나요?
퍼시스턴스 프레임워크는 크게 SQL Mapping, ORM 두 가지 종류로 나눌 수 있습니다.
SQL Mapping의 대표적인 도구로는 MyBatis가 있습니다. 객체와 DB 데이터를 자동으로 매핑하지 않고, SQL 쿼리를 통해 직접 데이터를 제어합니다.
ORM의 대표적인 도구로는 Hibernate, JPA 등이 있습니다. 객체와 DB 테이블 간의 매핑을 자동으로 처리합니다.
SQL Mapping 프레임워크 : MyBatis
MyBatis
- 특징- 개발자가 직접 SQL 쿼리를 작성하고, XML 파일 또는 어노테이션을 통해 SQL 쿼리를 매핑합니다.
- 장점
- SQL쿼리를 직접 작성하기 때문에, 복잡한 쿼리나 성능 최적화가 필요한 경우 유연하게 대처할 수 있습니다. - 단점
- SQL쿼리로 CRUD기능을 직접 작성해야 하기 때문에 반복적인 코드가 발생할 수 있으며 코드 재사용성이 떨어집니다.
- SQL과 Java 코드가 분리되어 있기 때문에 유지보수가 어려울 수 있습니다.
→ XML파일에 쿼리를 작성하는 대신 어노테이션을 통해 작성하면 물리적인 분리는 해결되지만, 복잡한 쿼리의 가독성 문제와 재사용성 부족 등의 문제는 여전히 존재할 수 있습니다. - 주요 기능
- 조건에 따라 동적으로 SQL 쿼리를 생성할 수 있습니다.
ORM (Object-Relational Mapping) 프레임워크: JPA, Hibernate
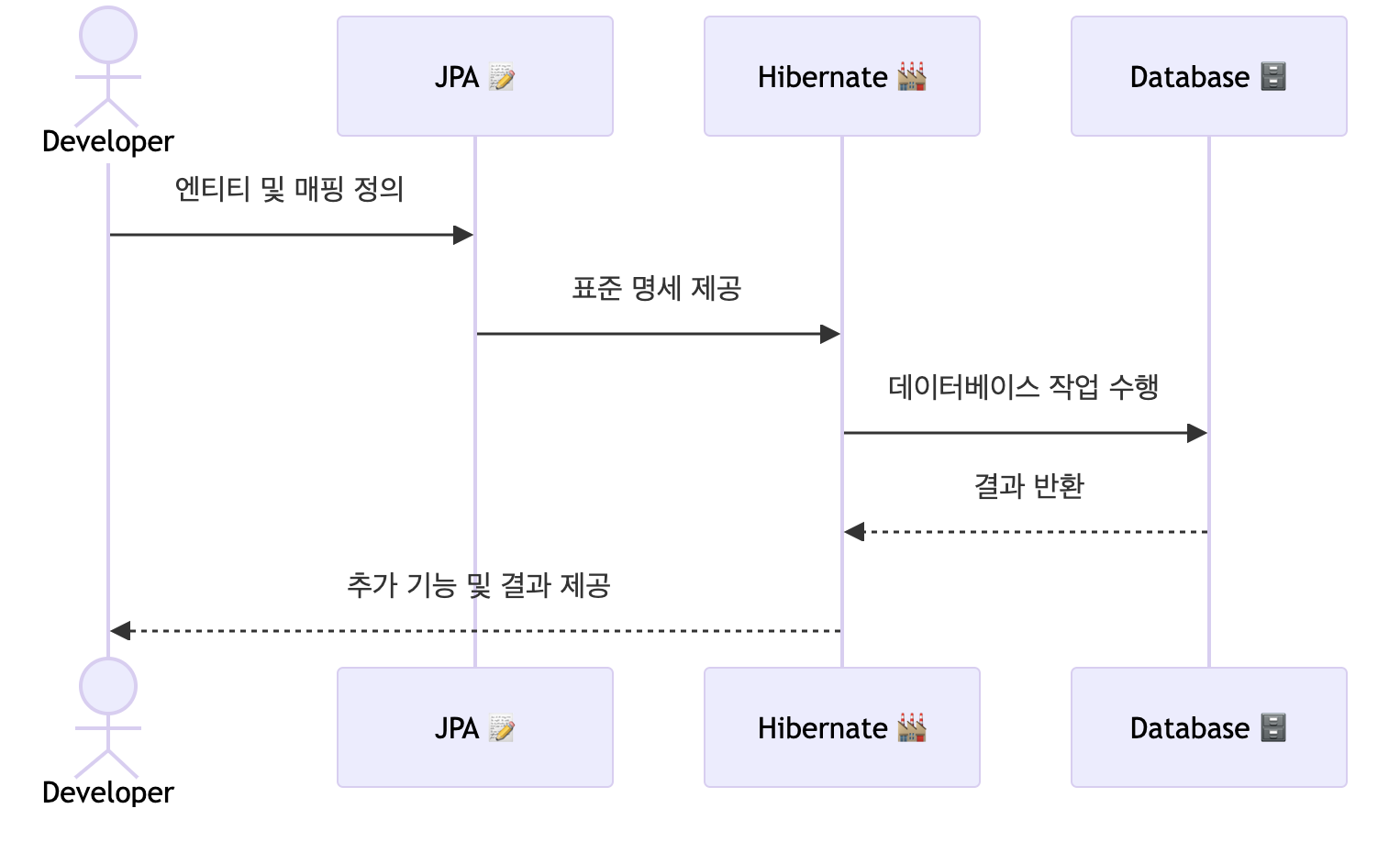
JPA와 Hibernate의 관계는 표준 명세(JPA)와 그 구현체(Hibernate)로 이해할 수 있습니다.
JPA는 표준 인터페이스와 규칙을 제공하고, Hibernate는 그 규칙을 구현한 강력한 ORM 프레임워크입니다.
JPA는 자동차를 만들기 위한 설계도와 같은 것입니다. 설계도에는 자동차가 어떤 기능을 가져야 하는지, 어떤 부품들이 필요한지에 대한 명세가 적혀 있습니다.
Hibernate는 이 설계도를 바탕으로 실제 자동차를 만드는 제조사입니다. 제조사는 설계도의 내용을 바탕으로 자동차를 만들지만, 제조사 나름의 기술과 추가 기능을 더해 더 나은 자동차를 만들 수도 있습니다.
JPA (Java Persistence API)
- 특징
- 자바의 공식 ORM 표준 명세입니다.
- 인터페이스를 제공하며, Hibernate, EclipseLink등의 여러 구현체가 있습니다.
- 데이터베이스와 직접 상호작용하는 코드를 많이 작성할 필요가 없어 코드의 의존성을 줄입니다. - 장점
- 특정 구현체에 종속되지 않아 다양한 JPA 구현체로 쉽게 전환할 수 있습니다.
- 표준 인터페이스를 사용하여 코드의 유지보수가 용이합니다.
- 다양한 JPA 구현체를 통해 기능을 확장할 수 있습니다. - 단점
- 복잡한 쿼리 작성이 어려울 수 있습니다. - 주요 기능
- 클래스와 데이터베이스 테이블을 매핑하고 엔티티의 상태를 관리합니다.
- JPQL을 사용하여 데이터베이스 쿼리를 작성합니다.
Hibernate
- 특징
- JPA의 대표적인 구현체 중 하나입니다.
- 자동으로 SQL을 생성해줍니다. - 장점
- 캐싱, 페이징, 배치 처리 등의 풍부한 기능과 다양한 데이터베이스 지원으로 유연하고 성능 최적하가 용이합니다. - 단점
- 자동화된 기능으로 인한 퍼포먼스 오버헤드가 발생할 수 있습니다. - 주요 기능
- 데이터베이스와 상호작용하는 기본 단위는 '세션'입니다.
- HQL(Hibernate Query Language)를 사용하여 쿼리를 작성합니다.
- 데이터베이스 접근을 줄이기 위해 1차 및 2차 캐시를 제공합니다.
- 패치 전략을 설정하여 성능을 최적화합니다.
MyBatis vs JPA,Hibernate 비교
| 특징 | MyBatis | JPA + Hibernate |
| 쿼리 작성 방식 | SQL을 직접 작성 | JPQL/HQL 사용 → 자동 SQL 생성 |
| 유연성 | 복잡한 쿼리 작성에 용이 | 복잡한 쿼리 작성에 제한이 있을 수 있음 |
| 디버깅 | 명시적인 SQL로 디버깅에 용이 | 자동 생성된 SQL로 디버깅이 어려울 수 있음 |
| 데이터베이스 종속성 | 특정 데이터베이스 기능 활용 가능 | 특정 데이터베이스 기능 사용 어려운 |
| 캐싱 | 1차 캐시 제공 2차 캐시는 Mapper 레벨에서 EHCache, Hazelcast, Redis 등 다양한 캐시 구현체를 사용 |
1차 및 2차 캐싱 제공 |
| 적절한 상황 | - 복잡한 SQL을 작성해야 하는 경우 - 특정 DB의 고유 기능을 사용해야 하는 경우 - 퍼포먼스 최적화가 중요한 경우 |
- 프로젝트가 DDD나 객체 지향적 패러다임을 강조하는 경우 - 표준을 준수해야 하는 경우 - 추후 DB를 변경할 가능성이 높은 경우 - 프로젝트가 주로 CRUD 작업으로 구성된 경우 |
어떻게 동작하나요?
MyBatis

JPA+Hibernate

사용 예제
MyBatis
1. XML 파일 사용
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper">
<select id="findById" parameterType="long" resultType="com.example.model.User">
SELECT * FROM users WHERE id = #{id}
</select>
<select id="findAll" resultType="com.example.model.User">
SELECT * FROM users
</select>
<insert id="insert" parameterType="com.example.model.User" useGeneratedKeys="true" keyProperty="id">
INSERT INTO users(name, email) VALUES(#{name}, #{email})
</insert>
<update id="update" parameterType="com.example.model.User">
UPDATE users SET name=#{name}, email=#{email} WHERE id=#{id}
</update>
<delete id="delete" parameterType="long">
DELETE FROM users WHERE id=#{id}
</delete>
</mapper>2. 어노테이션 사용
주로 간단한 쿼리에 적합함. XML 파일은 동적 SQL, SQL 분기, 반복문 등을 쉽게 처리할 수 있는 다양한 MyBatis 기능을 제공하는데 어노테이션은 이런 기능을 모두 활용하기 어려울 수 있음. SQL 인젝션 공격에 취약해질 수 있음.
import org.apache.ibatis.annotations.*;
import java.util.List;
@Mapper
public interface UserMapper {
@Select("SELECT * FROM users WHERE id = #{id}")
User findById(Long id);
@Select("SELECT * FROM users")
List<User> findAll();
@Insert("INSERT INTO users(name, email) VALUES(#{name}, #{email})")
@Options(useGeneratedKeys = true, keyProperty = "id")
void insert(User user);
@Update("UPDATE users SET name=#{name}, email=#{email} WHERE id=#{id}")
void update(User user);
@Delete("DELETE FROM users WHERE id=#{id}")
void delete(Long id);
}
JPA + Hibernate
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User getUserById(Long id) {
return userRepository.findById(id).orElse(null);
}
public List<User> getAllUsers() {
return userRepository.findAll();
}
public void createUser(User user) {
userRepository.save(user);
}
public void updateUser(User user) {
userRepository.save(user);
}
public void deleteUser(Long id) {
userRepository.deleteById(id);
}
}그럼 JDBC는 뭔가요?
대부분의 퍼시스턴스 프레임워크는 내부적으로 JDBC API를 사용하여 데이터베이스와 상호작용합니다.
퍼시스턴스 프레임워크는 이 JDBC API 위에 추가적인 추상화 계층을 제공하여 개발자의 편의를 도모합니다.
MyBatis는 내부적으로 JDBC API를 통해 데이터베이스와 통신합니다.
Hibernate는 JPA의 구현체로서 JDBC를 사용합니다.
개발자는 직접적인 JDBC 코드 작성을 하진 않지만 내부적으로는 여전히 JDBC가 사용되고 있습니다.
'DB' 카테고리의 다른 글
| MySQL Workbench 스키마 생성 / 테이블 생성 / 필드 생성 (0) | 2024.05.31 |
|---|---|
| [MAC M1 Pro] mysql 삭제 / 설치 / 실행 / 중지 / 상태확인 / 초기설정 / 접속 / 에러해결 (0) | 2024.05.31 |